T5 语音工具使用和分析文档
更新时间:2025-08-27 07:40:42LLM 副本以 Markdown 格式查看下载 PDF
操作步骤如下
1. 下载工具tyutool_gui.exe
2. 打开功能宏(先看app底下的readme),SDK版本需要在3.12.16及以上版本:ENABLE_AUDIO_ANALYSIS
3. 工具配置和说明:
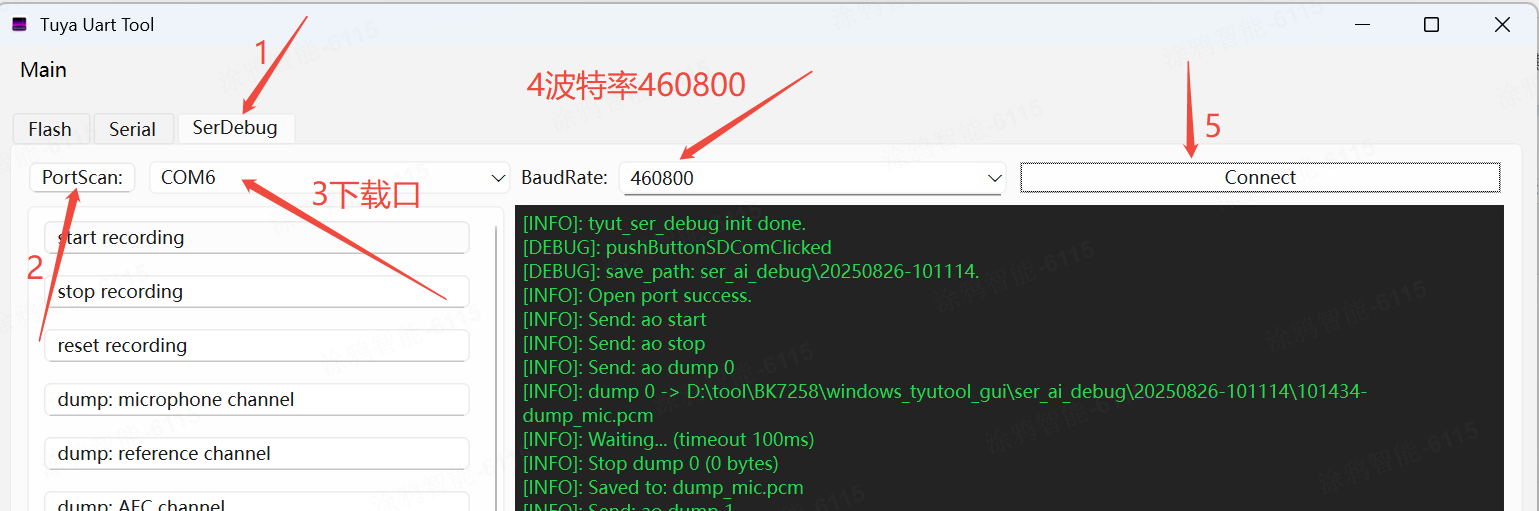
3. 点击start recording菜单 ,然后打开设备的日志口(用串口工具),如下:
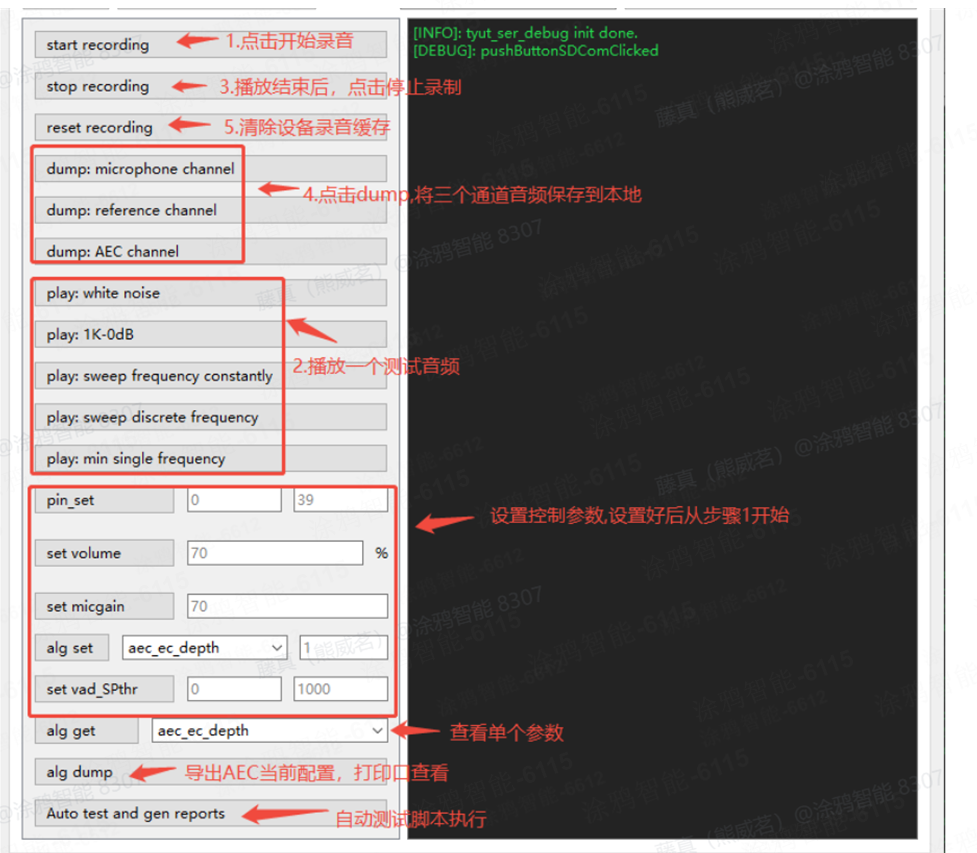
输出Mic通道的数据 - 输出回采通道的数据 = AEC处理后的数据
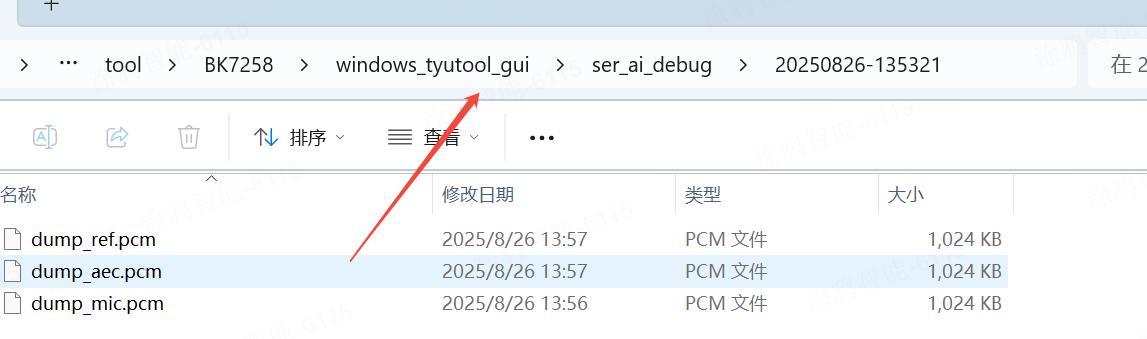
4. 采集成功会在工具的路径下面生成对应的PCM文件,如下:
5. 然后用脚本对采集的音频进行分析,输入下面指令(对应自己的文件名和路径):
脚本路径:apps/tuyaos_demo_ai_toy/scripts/audio_test.py
python audio_test.py --mic1 dump_mic.pcm --ref dump_ref.pcm --test all
如果提示这个错误:
ModuleNotFoundError: No module named 'numpy'
解决:pip install numpy
ModuleNotFoundError: No module named 'soundfile'
解决:pip install soundfile
ModuleNotFoundError: No module named 'scipy'
解决:pip install scipy
ModuleNotFoundError: No module named 'matplotlib'
解决:pip install matplotlib
6. 然后会有结果生成出来:
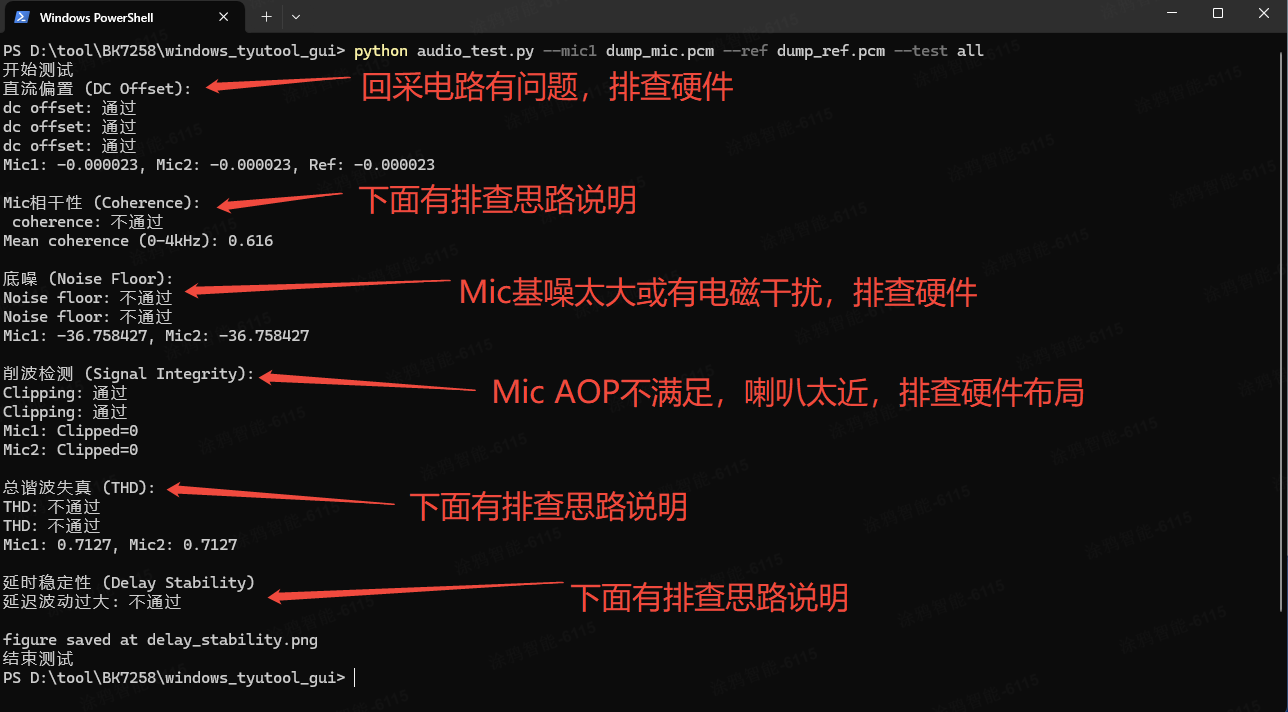
下面的调试指导仅供参考,以实际测试为准
MIC相干性:选择(高、中、低)灵敏度高一些的mic。
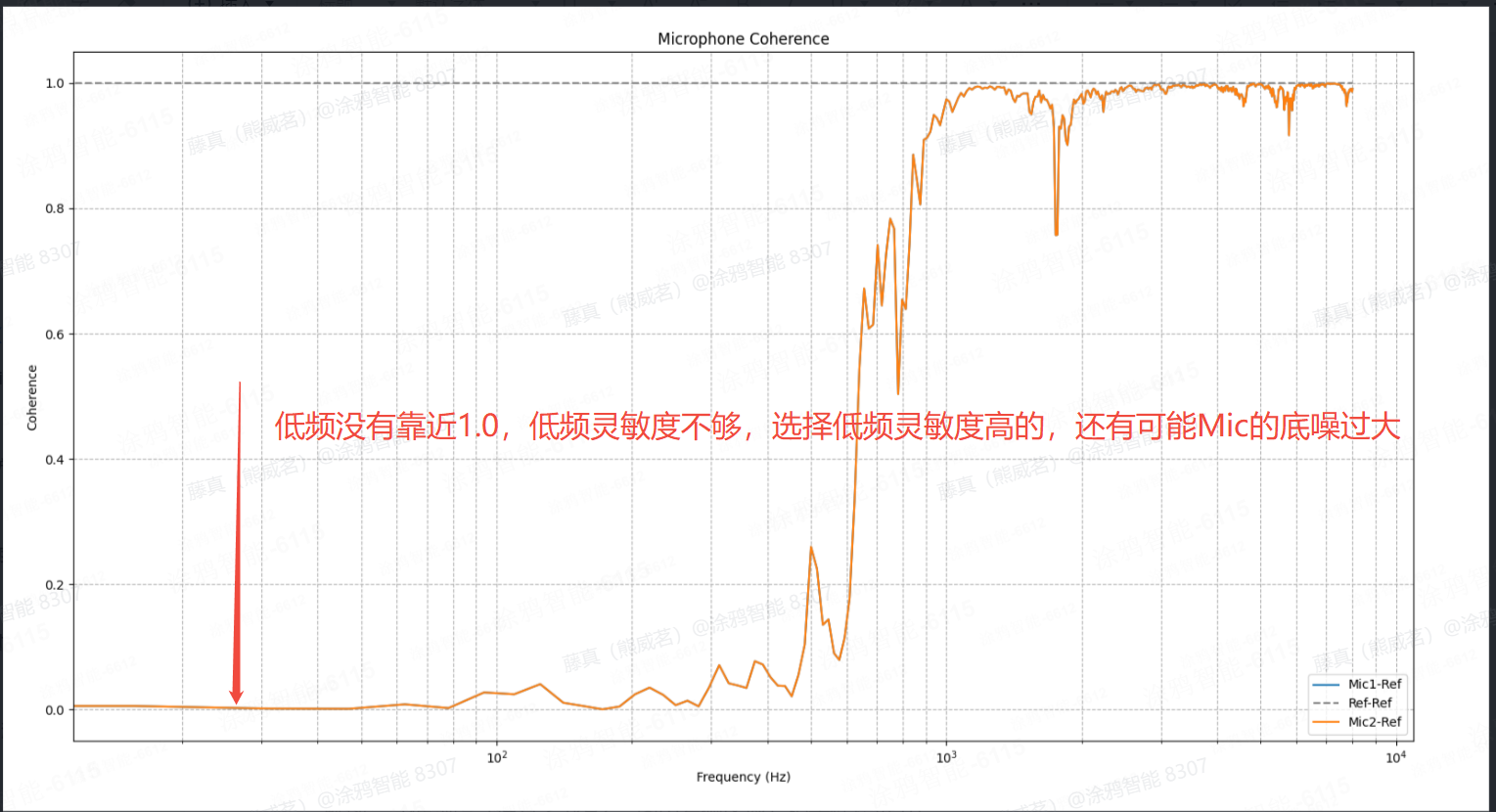
总谐波失真 (THD):
1.先查信号过载:降低 1kHz 信号幅值(如从 94dB SPL 降至 60dB SPL),重新测试 —— 若 THD 恢复合格,说明是 “幅值超过设备线性范围”,需调整增益或电源;
2.再查硬件非线性:替换核心元件(如换用高质量运放、新麦克风),对比 THD 变化 —— 若替换后合格,说明是元件本身性能不足;
3.最后查电路 / 环境:检查电源纹波(用示波器测电源电压)、线缆屏蔽、测试信号纯度 —— 排除干扰或参数设置问题。
延时稳定性 (Delay Stability):
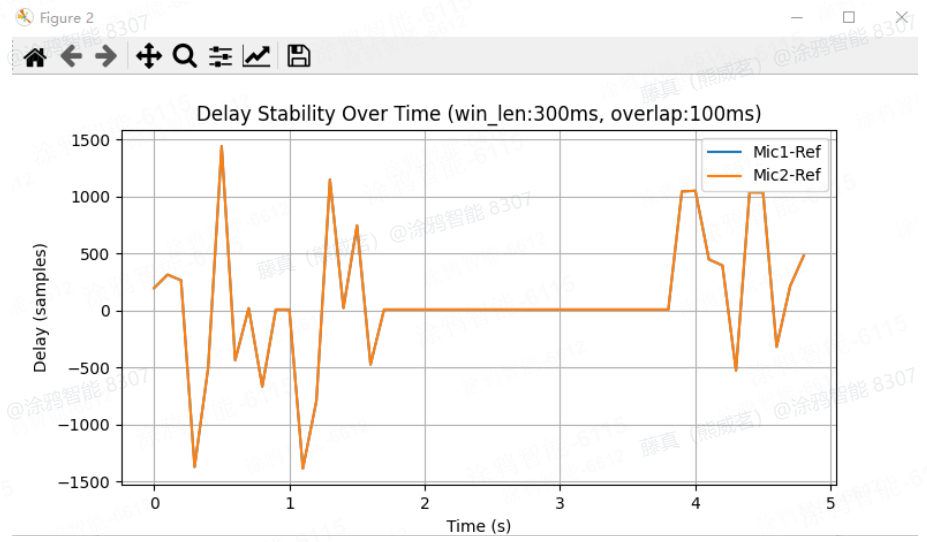
原理:核心看 延迟(Delay)的波动幅度和规律,判断麦克风信号与参考信号的同步性(越接近0越好)
解读:图中橙色曲线(Mic2-Ref)波动极大,延迟在 -1500 ~ +1500 samples 间剧烈变化 → 麦克风与参考信号的同步性极差,延迟极不稳定
改动点:(尝试修改麦克风延迟补偿值)
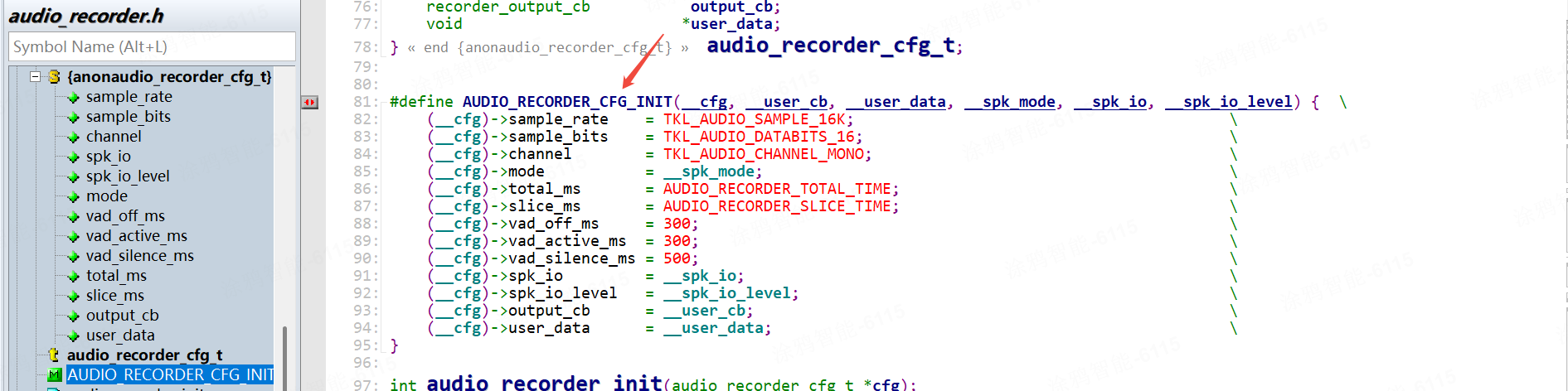
vad_config (在这个头文件里 \TuyaOS\apps\tuyaos_demo_ai_toy\srcaudio_recorder.h)
| 参数 | 含义 | 作用 |
|---|---|---|
| start_threshold_ms | VAD 激活(判定为 “有语音”)的持续时间,单位 ms | 当检测到语音信号时,需持续 300ms 才判定为 “有效语音”,避免短暂噪声误触发(如突发杂音)。 |
| silence_threshold_ms | VAD 失活(判定为 “无语音”)的持续时间,单位 ms | 当语音消失后,需持续 500ms 无语音才判定为 “静音”,避免语音中间的短暂停顿被误判为结束(如说话时的自然换气) |
| end_threshold_ms | VAD 静音超时时间,单位 ms | 若持续 30 秒未检测到语音,自动结束录音或重置 VAD 状态,避免长时间无语音时的无效等待 |
| vad_frame_duration | VAD 的检测帧长,单位 ms | 将音频按 10ms 为一帧进行 VAD 分析,帧长越短,VAD 响应越灵敏(但计算量越大),10ms 是语音处理的常用帧长 |
| scale | 灵敏度系数 | 调整语音检测的敏感度(0.1~3.0),值越小越敏感 |
SPthr (在这个源文件里 /vendor/T5/tuyaos/tuyaos_adapter/src/driver/tkl_audio.c)
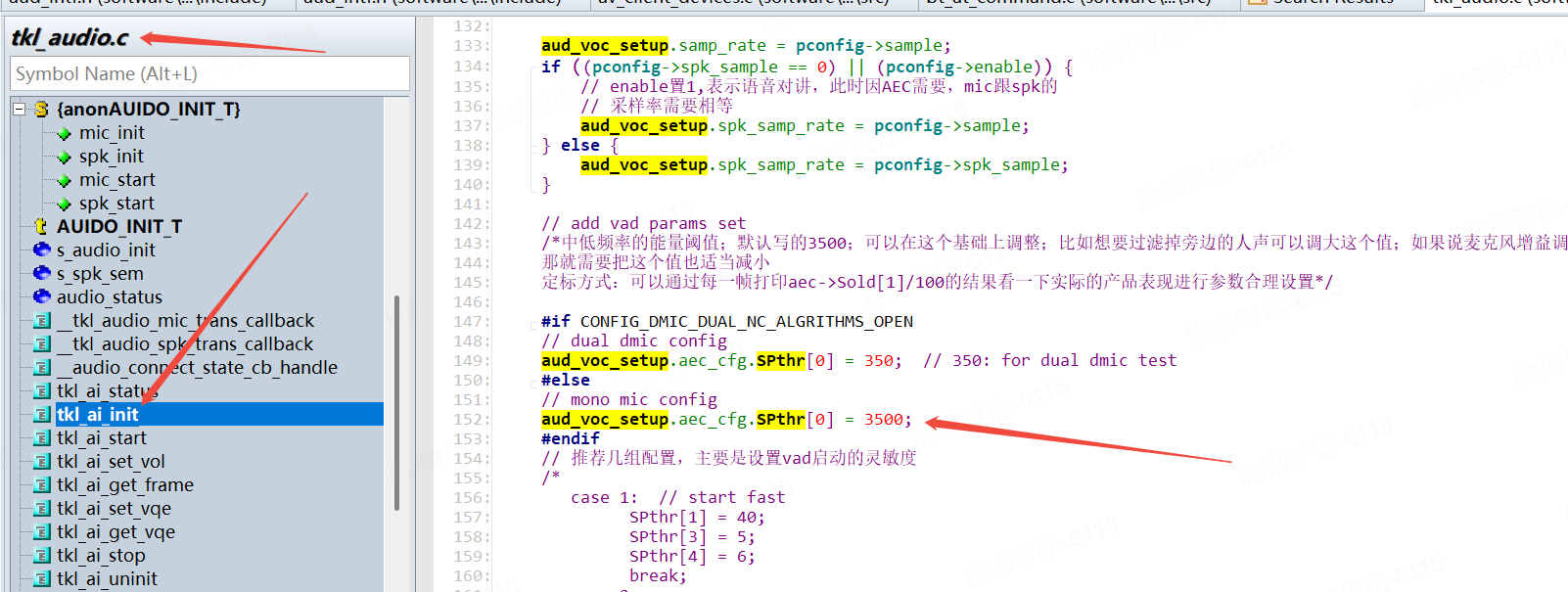
| 参数 | 作用 |
|---|---|
| SPthr[0](中低频能量阈值) | VAD 判断的 “基础能量门槛”,用于过滤低能量的噪声(如环境杂音、电流声) |
| SPthr[1](vad激活分数阈值) | 决定 VAD 从 “非激活” 到 “激活(判定为语音)” 的触发门槛。 |
| SPthr[2](累计分数上限) | 限制 VAD 累计分数的最大值,避免分数无限增长影响 “语音结束” 的判断。 |
| SPthr[3](语音帧评分权重(高概率)) | 对 “高概率为语音” 的音频帧,在累计分数时的加权值。 |
| SPthr[4](语音帧评分权重(中概率) | 对 “中概率为语音” 的音频帧(如带轻微噪声的语音)的加权值。 |
| SPthr[5](静音衰减步长) | 当判定为 “静音帧” 时,累计分数的衰减速度(每帧减少的值)。 |
| SPthr [6]~SPthr [13](VAD 能量阈值辅助参数) | 这些参数是更精细的能量判断标准,用于补充基础阈值(SPthr [0]),通常与不同频段、时间窗口或能量比例相关 |
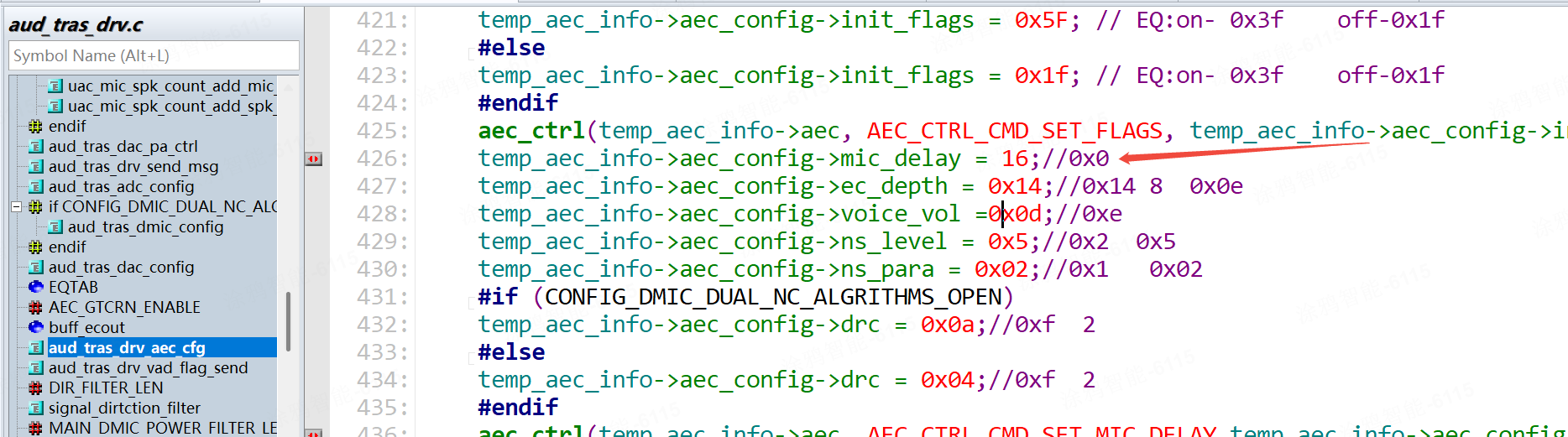
AEC参数列表(vendor/T5/t5_os/components/multimedia/aud/aud_tras_drv.c)
| 参数 | 作用 | 默认值(参考值) | 使用方式(场景) |
|---|---|---|---|
| ec_depth(回声消除深度) | 控制回声消除算法的强度,值越大,对回声的抑制能力越强。 | 20 (1-50) | ○强回声场景(如空旷房间、扬声器音量大、麦克风灵敏度高):设为 30~50(如会议室用音响外放时)。○弱回声场景(如小房间、耳机通话、低音量播放):设为 1~10(避免过度处理导致语音模糊)。 |
| mic_delay(麦克风延迟补偿值) | 麦克风采集信号与扬声器播放信号的时间差(单位:采样点) | 0 (ms * Khz) | ○硬件延迟场景(如音频通过蓝牙传输、视频通话中音视频同步导致的延迟):通过分析 dump 数据中的回声信号与原始信号的时间差,设置对应采样点(例如延迟 10ms,采样率 48kHz 时,延时 = 10×48=480 采样点,设为 480)。○若未校准,AEC 会因回声信号与参考信号 “不同步” 而失效,导致回声残留。 |
| ref_scale (参考信号缩放) | 调整 “参考信号”(即远端传来的语音,也是回声的源头)的幅度(0 = 最小,2 = 最大) | 0 (0、1、2) | ○远端信号弱(如对方说话声音小):设为 1 或 2,增强参考信号幅度,帮助 AEC 更精准识别回声。○远端信号过强(如对方音量过大导致参考信号失真):设为 0,避免参考信号过载影响回声判断。 |
| voice_vol (语音音量) | 调整经过 AEC 处理后的音频输出音量 | 需要查看芯片手册 | ○本地环境嘈杂(如户外通话):增大值(如 15~20),让对方更清晰听到你的声音。○本地环境安静(如办公室):减小值(如 10~12),避免音量过高刺耳。 |
| TxRxThr & TxRxFlr(发送 / 接收阈值(上下限) | 两者配合定义 “双工通话”(双方同时说话)时的幅度判断范围,控制本地语音(发送)和远端语音(接收)的平衡,避免一方声音被过度压制 | 上 30(20~50)下 6(3 ~10) | ○需优先保证本地语音发送(如演讲者发言):提高 TxRxThr(如 40),降低 TxRxFlr(如 4),扩大 “本地语音优先发送” 的范围。○双工平等场景(如普通聊天):保持默认值,确保双方同时说话时,声音都能被清晰传输(既不压制本地,也不忽略远端)。 |
| ns_level ( 噪声抑制级别) | 控制对背景噪声(如电流声、环境杂音)的消除强度,值越大,降噪越强(但可能损失语音细节) | 5(1~8) | ○高噪声环境(如地铁、菜市场):设为 6~8,强力抑制背景噪声。○低噪声环境(如安静卧室):设为 1~3,保留更多语音细节(避免 “消声过度” 导致声音发闷)。 |
| ns_para (噪声抑制参数) | 对ns_level的精细调节,值越小,对语音的保护越强(减少因降噪对语音的损伤) | 2(0、1、2) | ○噪声略高但语音较清晰(如办公室有空调声):ns_level=5时,ns_para=2(增强降噪)。○噪声极低(如专业录音室):ns_level=1时,ns_para=0(最小化对语音的影响)。 |
| drc (动态范围压缩) | 平衡音频的动态范围(即 loud 与 soft 声音的差距),值越大,压缩越强,可使小声更清晰、大声不过载 | 4(0x10~0x1f) | ○音量波动大的场景(如车载通话,时远时近讲话):设为 0x1f(31),强压缩让音量更稳定。○需要保留语音动态的场景(如播客录制):设为 0x10(16),弱压缩保留自然的音量起伏。 |
7. 想更深入的了解声学,可以查看以下文档。
https://doc.weixin.qq.com/doc/w3_AR0AegZIAOYCNRCmtWTOGTSG1twjZ?scode=AGQAugfWAAkcqlzACfAJMAEgYIAFA
该内容对您有帮助吗?
是意见反馈该内容对您有帮助吗?
是意见反馈
关注“涂鸦智能”
涂鸦服务尽在掌握

关注“全球智能商业”
第一时间获取物联网资讯




