声纹识别
功能简介
声纹识别是平台提供的用于设备端智能体识别 是谁在说话 的一项语音交互能力。
不同于传统语音识别(Automatic Speech Recognition,ASR)仅关注 说了什么,声纹识别可在语音交互中识别说话人身份,使 AI 设备具备对不同用户进行区分和响应的能力。
该能力作为语音交互中的 身份层,可帮助设备从 理解内容 进一步升级为 理解说话人。
使用场景
抗干扰交互(指定用户响应)
在家庭或办公等多人环境中,设备仅识别并响应指定用户的语音输入,屏蔽其他背景人声干扰。
例如:
- 仅响应设备主人指令。
- 忽略电视声或旁人对话。
多人对话识别(对话标注)
在多人交互场景中,设备可自动区分不同说话人,并在对话记录中进行标注。
例如:
- 聊天记录中区分 谁说了什么。
- 支持多人对话上下文理解。
轻量会议记录(临时身份归类)
在临时交流或会议场景中,设备可自动识别并归类不同说话人(即使未提前录入声纹),并在一段时间内持续识别为同一人。
例如:
- 自动生成带 说话人标识 的记录。
- 支持临时对话人跟踪。
开启方式
平台侧开启
在智能体开发流程中的 模型能力配置 > 语音交互 板块,可以开启 声纹识别,同时也可以选择开启附加功能 自动录入陌生声纹。开启后需发布智能体版本方可生效。
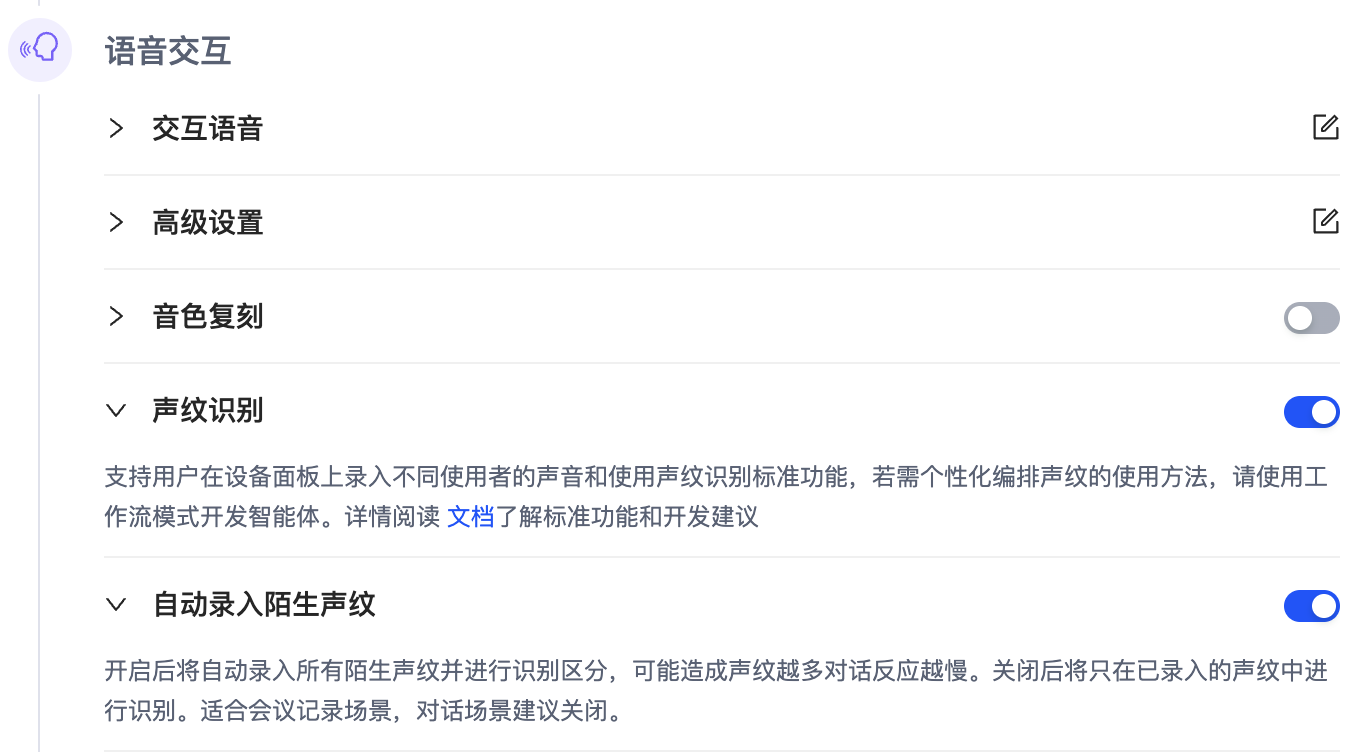
用户侧开启
平台开启并发布后,仅代表绑定了该智能体的产品(PID)下的设备已具备声纹识别处理能力,但不会自动对终端用户生效,仍需用户在设备面板中手动开启 声纹识别 功能后,方可进行声纹录入和使用。
了解如何绑定智能体,请查看 如何绑定智能体。
用户侧体验说明
使用涂鸦通用 AI 面板/涂鸦硬件方案免开发面板
当设备激活后,用户可在面板中看到 声纹识别 入口,并进入功能页面进行管理和使用。以通用 AI 面板交互为例:
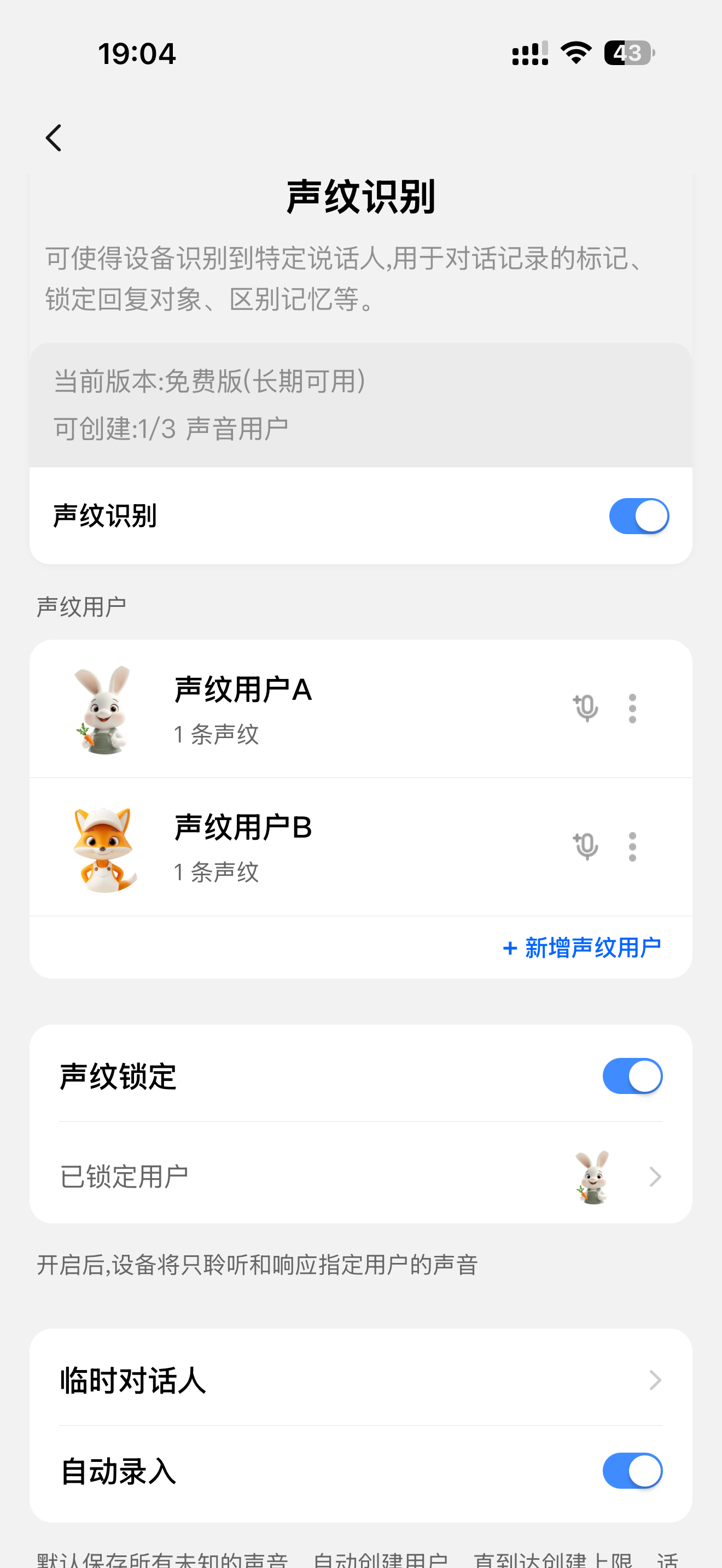
主要功能包括:
- 声纹用户管理:用户可录入自己及家庭成员的声音作为声纹样本,支持:新增/删除用户、替用声纹录入。
- 声纹识别开关:开启后,每轮对话将自动进行声纹识别处理。
- 声纹锁定:设备仅响应指定声纹用户的语音输入,其余声音不作响应。
- 自动录入:无需手动录入声纹样本,设备将自动记录陌生声音特征,并在一定时间内识别为同一 临时用户。可用于会议记录等场景。
使用自定义面板
若您使用自定义开发面板,涂鸦将提供声纹识别小程序页面组件及相关 SDK 能力支持,以协助您完成功能开发与集成。请关注小程序开发平台更新。
计费说明
声纹识别属于 AI 扩展能力,不包含在 AI 基础资源消耗的减免政策中。
您可通过下文介绍的两种方式进行开通与使用:
方式一:订阅模式(推荐)
将产品(PID)加入 订阅模式,平台将统一为每台设备提供每日免费和付费的 AI 使用额度,并对超额使用进行柔性限制,当用户在 App 侧订阅付费服务时,设备可使用声纹识别功能。
详细请参考 智能体投放及费用 中关于订阅模式的相关介绍。
方式二:按量计费模式
若您的设备因使用声纹识别产生额外的 AI 资源消耗,且已超出设备本身减免额度时,平台将会根据实际产生的消耗量进行计量,您需购买额度抵扣以确保智能体的正常运行。该模式下,您需自行完成设备端的使用量限制和订阅收费等功能,涂鸦不对设备的声纹识别次数作统一限制管理。
关于声纹识别的计量规则及报价,请参考 计量计费说明。
隐私与数据安全
区域限制
当前功能仅支持中国区、印度区、新加坡区使用。
用户授权要求
声纹识别涉及生物特征数据,需严格获取用户授权;使用涂鸦官方面板时,已内置授权流程;使用自定义面板时,需自行实现授权逻辑。
数据存储策略
声纹数据在云端进行加密存储,用户录入的声纹会长期保存(直至用户删除),临时声纹则保留 24 小时后自动清除。
其他说明
声纹数量限制
声纹识别时会对当前用户家庭下录入的所有声纹(含替用声纹)进行识别,随声纹数量的增加,会造成设备反馈延迟、准确率下降等问题。为确保识别效果,当前功能仅支持一个家庭下录入 5 个声纹用户(最多 15 条声纹)和 5 个临时声纹。
准确性说明
声纹识别准确性与录入音频的质量、环境噪音、数量、会话长度等均有关联。小规模场景下识别成功率超过 97%,超过 20 条声纹时成功率可能会下降到 92%~95%,具体识别准确率以设备实际表现为准。
延迟说明
声纹识别将增加对话处理时长,网络环境较好情况下平均延迟 200~400 ms,具体延迟时长以设备及所在环境为准。
使用边界
- 声纹识别能力仅用于语音身份标记,不具备强认证能力,且无法保证 100% 准确。
- 声纹不可替代登录或支付验证,同时也不适用于法律或安全关键场景。
该内容对您有帮助吗?
是意见反馈该内容对您有帮助吗?
是意见反馈





