Tuya OmniMem: AI Memory System
OmniMem is the Tuya in-house AI memory system designed for multi-device IoT scenarios. It addresses key engineering challenges in long-term memory management for AI agents: cross-session memory loss, fragmented memory across devices, high recall latency, and insufficient accuracy.
The system supports a dual-channel architecture for short-term memory (session level) and long-term memory (user level). It delivers millisecond-scale recall latency and more than 75% memory accuracy (Pro edition). Through a unified memory layer, OmniMem enables seamless memory sharing across multiple agents and devices.
Technical solution and evolution
Technical advantages
OmniMem stands out in three aspects:

- Architecture: Dual-channel memory plus a unified memory graph balance response speed and information depth.
- Algorithms: Targeted optimizations such as temporal semantic parsing, interference elimination, and conflict resolution address real-world engineering challenges.
- Engineering: Millisecond-scale recall, real-time incremental updates, and configuration-based integration deliver production-grade performance and ease of use.
For developers building persistent AI memory capabilities in multi-device IoT scenarios, OmniMem provides a complete solution from out-of-the-box deployment to advanced customization.
Use cases
| Scenario | Memory capability | Key technologies |
|---|---|---|
| Companion toys | • Long-term preference memory • Growth records • Personalized conversations |
• Long-term memory • Emotional weighting |
| Smart home | • Device state memory • User habit learning • Scene linkage |
• Cross-agent memory graph • Real-time updates |
| Travel assistant | • Cross-timeframe context integration • Travel preference accumulation |
• Temporal parsing • Long-term memory |
| Personalized recommendations | • Dynamic user profiles • Preference change tracking |
• Full-channel memory • Dynamic updates |
Technology roadmap
| Direction | Current status | Planned goal |
|---|---|---|
| Memory emotional weight model | Completed | Weight memories by emotional intensity to optimize recall ranking and natural expression. |
| Seamless cross-device migration | Planned | Package memory data → unbind device identity → sync to new device, with voiceprint-associated migration. |
| Multimodal memory fusion | In development | Map cross-modal semantics to associate image and video frame features with text memories. |
| Memory security and compliance | Ongoing iteration | Support device-side encrypted storage, memory data ownership, and GDPR-compliant data deletion. |
System architecture
OmniMem uses a five-layer pipeline: Input Layer → Preprocessing Layer → Processing Layer → Management Layer → Storage Layer.
Architecture overview
┌─────────────────────────────────────────────────────────────────┐
│ Input Layer │
│ Multimodal data collection (voice, text, events) │
└──────────────────────────────┬──────────────────────────────────┘
▼
┌─────────────────────────────────────────────────────────────────┐
│ Preprocessing Layer │
│ Data cleansing → PII filtering → Interference signal filtering │
└──────────────────────────────┬──────────────────────────────────┘
▼
┌────────────────────────┬─────┴─────┬────────────────────────────┐
│ Short-term Memory │ │ Long-term Memory │
│ │ │ │
│ Semantic extraction │ │ Entity extraction │
│ → Summarization │ │ → Relationship mapping │
│ → Lightweight summary │ │→ Standardized transcription│
│ │ │ → Weight tagging │
└────────────────────────┴─────┬─────┴────────────────────────────┘
▼
┌─────────────────────────────────────────────────────────────────┐
│ Management Layer │
│ Real-time incremental updates + Offline optimization │
│ + Periodic memory decay │
└──────────────────────────────┬──────────────────────────────────┘
▼
┌─────────────────────────────────────────────────────────────────┐
│ Storage Layer │
│ Structured memory graph with multidimensional storage │
│ (entity, relation, attribute) │
└─────────────────────────────────────────────────────────────────┘
Layer responsibilities
| Layer | Responsibilities | Key technologies |
|---|---|---|
| Input layer | Collects and standardizes data from multiple sources. | • Multi-protocol adaptation • Streaming data ingestion |
| Preprocessing layer | Ensures data quality and compliance filtering. | • PII detection and masking • Noise filtering algorithm |
| Processing layer | Performs semantic understanding and structured memory extraction. | • Named entity recognition (NER) • Relationship graph construction • Sentiment analysis |
| Management layer | Manages the memory lifecycle. | • Incremental updates • Temporal decay • Conflict resolution |
| Storage layer | Stores and retrieves memory efficiently. | • Vector indexing • Graph database • Hierarchical caching |
Dual-channel memory model
Short-term memory
- Purpose: Maintains session-level context for coherent multi-turn interactions.
- Processing flow: Raw conversation → Semantic segmentation → Key information extraction → Summarization.
- Storage strategy: Uses a sliding window with Least Recently Used (LRU) eviction for lightweight and efficient operation.
- Recall latency: < 10 ms
Long-term memory
- Purpose: Maintains a persistent user profile for personalization and cross-session reasoning.
- Processing flow: Conversation text → Entity extraction → Relationship mapping → Attribute tagging (emotional weight, timestamp, and confidence) → Memory graph storage.
- Storage strategy: Uses a structured memory graph that supports multidimensional indexing and relationship-based queries.
- Recall latency: < 100 ms (millisecond-scale)
Performance benchmark
Based on evaluations using public datasets, the comparison between OmniMem and mainstream open-source memory solutions is as follows:
| Metric | OmniMem Pro | OmniMem Standard | Mem0 | MemGPT |
|---|---|---|---|---|
| Memory accuracy | > 75% | > 65% | ~55% | ~50% |
| Long-term memory recall latency | < 100 ms | < 100 ms | Seconds | Seconds |
| Memory dimension | Dual-channel (short-term and long-term) | Dual-channel (short-term and long-term) | Single-channel | Single-channel |
| Cross-agent memory sharing | Native support | Native support | Not supported | Not supported |
| Dynamic update mechanism | Real-time incremental updates and offline integration | Real-time incremental updates | Full overwrite | Full overwrite |
Advantages
- Recall latency: Cuts recall latency by an order of magnitude, from seconds to milliseconds, for real-time dialogue.
- Accuracy: Pro edition exceeds 75% accuracy versus 50–55% for open-source alternatives, reducing memory hallucinations and confusion.
- Multi-agent support: A unified memory layer natively supports cross-agent sharing and relational reasoning.
Key technical breakthroughs
Multilingual temporal semantic parsing
How temporal information is handled directly affects memory validity. OmniMem implements a time semantic parsing engine that covers complex scenarios:
- Time zone adaptation: Adjusts timestamps automatically based on the user’s profile and local time zone.
- Fuzzy time disambiguation: Supports natural language expressions such as
last week,National Day, andearly next month. - Temporal conflict detection: Triggers conflict resolution when new memories contradict existing memories in temporal order.
Memory interference elimination
OmniMem prevents task execution results from polluting long-term memory. For example, after the user issues the command "Set the air conditioner to 26°C", the successful execution of that command should not be retained as long-term memory or influence future interactions.
Technical solution:
- Intent-aware classification: Distinguishes user preference expressions from one-time operational commands.
- Pre-write memory filtering: Determines whether to persist memory based on intent classification results.
- Dynamic memory weighting: Accelerates the decay of operation memory, and permanently retains preference memory.
Cross-agent memory graph
To eliminate memory silos across multiple agents, OmniMem builds a unified structured memory graph.
┌───────────┐ ┌────────────┐ ┌─────────────┐
│ Agent A │ │ Agent B │ │ Agent C │
│ (Toy) │ │ (Speaker) │ │ (Appliance) │
└─────┬─────┘ └──────┬─────┘ └──────┬──────┘
│ │ │
└──────────────────┼──────────────────┘
▼
┌──────────────────────────────┐
│ Unified Memory Graph │
│ │
│ User Entity ←→ Preference │
│ ↕ ↕ │
│ Event Node ←→ Context Node │
│ ↕ ↕ │
│ Device State ←→ Time Axis │
└──────────────────────────────┘
- Entity-level unification: Maps memories from multiple agents to a unified user entity graph.
- Relationship-based reasoning: Supports multi-hop reasoning across conversations and scenarios.
- Conflict detection and merging: Automatically resolves conflicting memories generated by different agents based on confidence and timestamps.
Dual-mode dynamic updates
OmniMem combines real-time responsiveness with long-term consistency through a hybrid update strategy.
| Mode | Trigger | Processing logic | Use cases |
|---|---|---|---|
| Real-time incremental updates | During conversation | • Hot path writing • Asynchronous indexing |
• Immediate preference change • New event recording |
| Offline optimization and integration | Scheduled tasks or off-peak periods | • Redundancy merging • Expired memory cleanup • Graph optimization |
• Memory store compaction • Global consistency maintenance |
Integration
On the Tuya AI Developer Platform, enable the agent memory capabilities through configuration without additional development.
-
Log in and go to My Agent, then open the agent development page.
-
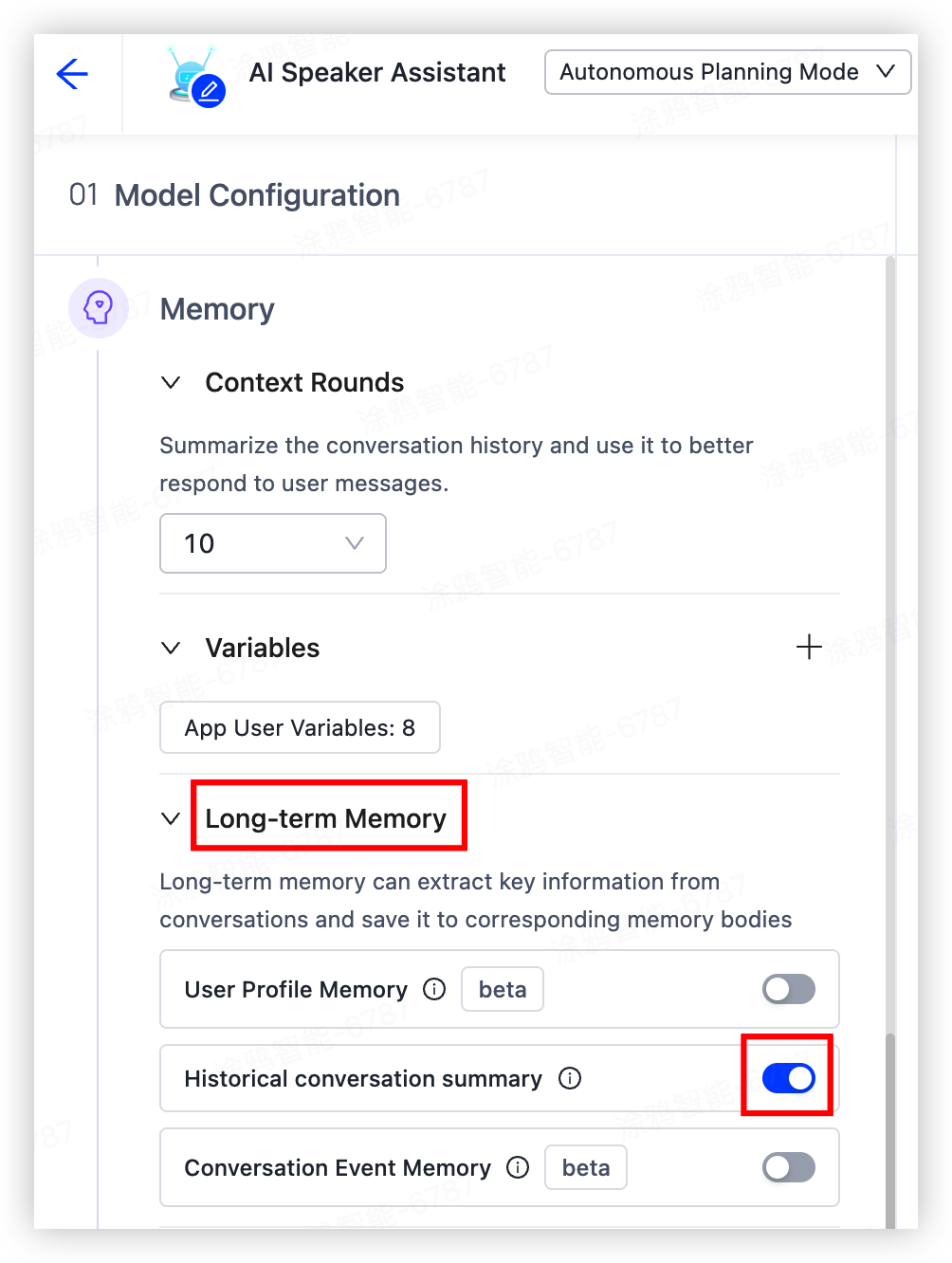
Go to Model Configuration > Memory > Long-term Memory, and enable the following memory capabilities based on your scenario:
- User profile memory
- Historical conversation summary
- Conversation event memory
OmniMem automatically collects, processes, stores, and recalls memories. You do not need to implement the underlying pipeline.
Is this page helpful?
YesFeedbackIs this page helpful?
YesFeedback




